Go 部落格
泛型的簡介
簡介
這篇部落格文章是基於我們在 GopherCon 2021 年的演講
Go 1.18 發布版本新增了泛型的支援。泛型是自開放原始碼首次發布以來,我們對 Go 做出的最大變更。在本文中,我們將介紹新的語言功能。我們不會試著涵蓋所有細節,但我們會介紹所有重點。若要取得更詳細且更長的說明,包括許多範例,請參閱 建議文件。若要取得更精確的語言變更說明,請參閱 更新的語言說明。(請注意,實際的 1.18 實作對建議文件允許的內容施加了一些限制;說明應準確無誤。未來的版本可能會解除其中一些限制。)
泛型是一種寫出不限於所使用的特定類型之程式碼的方法。函數和類型現在可以寫成可使用一組類型中的任何一個。
泛型為語言新增了三個重要的新功能
- 函數和類型的類型參數。
- 將介面類型定義為一組類型,包括沒有方法的類型。
- 類型推斷類型推論在很多情況下允許在調用函數時省略類型參數。
類型參數
函數和類型現在允許具有類型參數。類型參數列表看起來像一個平常的參數列表,只不過它使用方括號而不是圓括號。
為了說明它是如何運作的,讓我們從基本非泛型浮點值函數 Min 開始
func Min(x, y float64) float64 {
if x < y {
return x
}
return y
}
我們能夠通過新增類型參數列表來讓此函數泛型化,也就是讓它用於不同的類型。在此範例中,我們新增一個含有單一類型參數 T 的類型參數列表,並將 float64 的使用方式替換為 T。
import "golang.org/x/exp/constraints"
func GMin[T constraints.Ordered](x, y T) T {
if x < y {
return x
}
return y
}
現在可以通過撰寫像這樣的呼叫來使用含有類型參數的函數
x := GMin[int](2, 3)
提供給 GMin 的類型參數,在這個情況下是 int,稱為「實例化」。實例化分為兩個步驟進行。首先,編譯器會在泛型函數或類型中將所有類型參數替換為它們各自的類型參數。其次,編譯器會驗證每個類型參數是否符合各自的限制。我們不久就會了解它的意思,但如果第二個步驟失敗,實例化就會失敗,且程式會無效。
在成功實例化後,我們就會有一個非泛型的函數,它可以像任何其他函數一樣被呼叫。例如在像這樣的程式碼中
fmin := GMin[float64]
m := fmin(2.71, 3.14)
實例化 GMin[float64] 實際上會產生我們原始的浮點 Min 函數,我們可以在函數呼叫中使用它。
類型參數也可與類型搭配使用。
type Tree[T interface{}] struct {
left, right *Tree[T]
value T
}
func (t *Tree[T]) Lookup(x T) *Tree[T] { ... }
var stringTree Tree[string]
在此,泛型類型 Tree 儲存類型參數 T 的值。泛型類型可含有方法,例如此範例中的 Lookup。為了要使用泛型類型,就必須實例化它;Tree[string] 就是使用類型參數 string 實例化 Tree 的範例。
類型集合
讓我們更深入檢視用於實例化類型參數的類型參數。
一般函數為每個值參數具有類型;該類型定義一組值。例如,如果我們在非泛型函數中擁有 float64 類型,如同上方的 Min,允許的參數值集合就是 float64 類型所能表示的浮點值集合。
類似地,類型參數列表為每個類型參數具有類型。由於類型參數本身就是類型,因此類型參數的類型定義類型的集合。此元類型稱為「類型限制」。
在一般性的 GMin 中,類型約束導入自 constraints 套件。Ordered 約束描述了所有值可以排序的類型集合,或者換句話說,使用 < 運算子(或 <=、> 等等)比較。約束確保僅能將具有可排序值的類型傳遞給 GMin。它也表示在 GMin 函數主體中,該類型參數的值可以使用 < 運算子比較。
在 Go 中,類型約束必須是介面。亦即,介面類型可用作值類型,且也能用作元類型。介面定義方法,因此顯然我們可以表達需要存在特定方法的類型約束。但 constraints.Ordered 也是介面類型,且 < 運算子不是方法。
為了讓這運作,我們用一種新的方式觀察介面。
直到最近,Go 規格才表示介面定義方法組,這大致上是介面中列舉方法的集合。任何實作所有這些方法的類型皆實作該介面。

但是另一種觀察方式是說介面定義一組類型,也就是實作這些方法的類型。從這個角度來看,介面的類型組的任何元素類型皆實作介面。
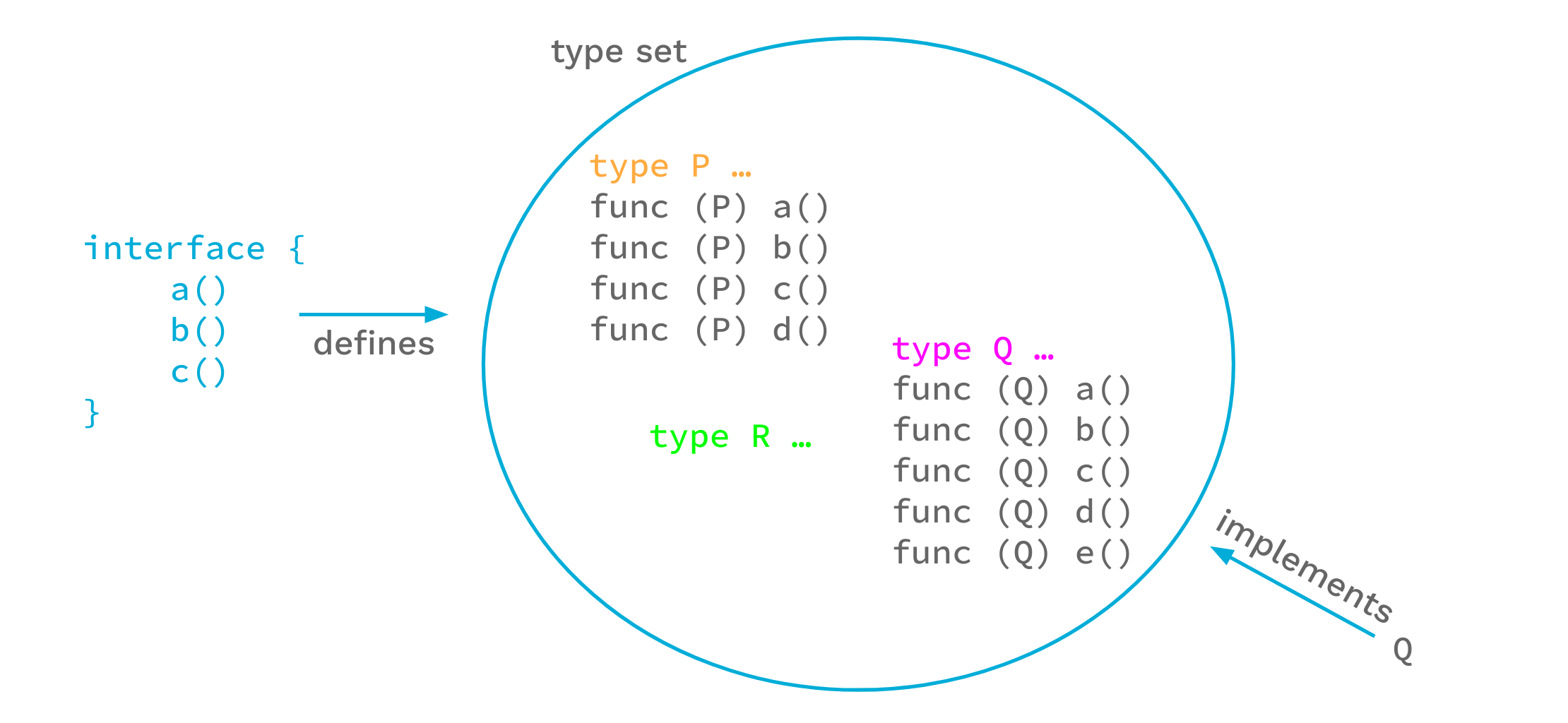
這兩個觀點會得到相同的結果:對於每組方法,我們可以想像實作這些方法的對應類型組,而這就是介面定義的類型組。
然而,對於我們而言,類型組觀點優於方法組觀點:我們可以明確地將類型新增到集合中,因此可以採用新的方式控制類型組。
我們已經擴充介面類型的語法,讓這運作。例如,interface{ int|string|bool } 定義包含 int、string 和 bool 型態的類型組。
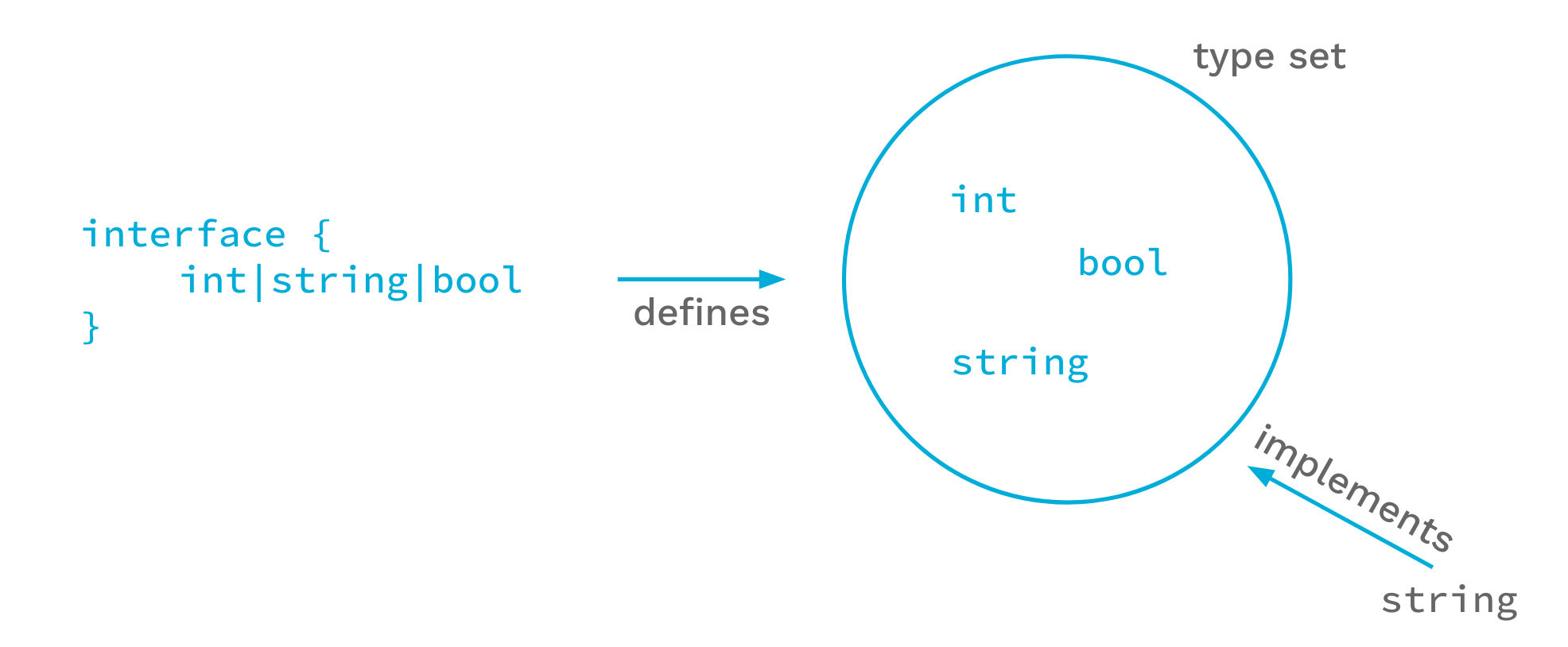
另一種說法是僅有 int、string 或 bool 能滿足此介面。
現在讓我們看看 constraints.Ordered 的實際定義
type Ordered interface {
Integer|Float|~string
}
這個宣告表示 Ordered 介面是所有整數、浮點數和字串類型的集合。垂直線表示類型的聯集(或者在這個情況下是類型的集合)。Integer 和 Float 是在 constraints 套件中以類似方式定義的介面類型。請注意 Ordered 介面沒有定義任何方法。
對於類型約束,我們通常不在乎具體的類型,例如 字串;我們感興趣的是所有字串類型。這就是 ~ 標記的作用。表達式 ~字串 表示底層類型為 字串 的所有類型的集合。這包括 字串 類型本身,以及使用定義宣告的所有類型,例如 類型 MyString 字串。
當然我們仍然想在介面中指定方法,而且我們要向後相容。在 Go 1.18 中,介面可以像以前一樣包含方法和嵌入式介面,但它也可以嵌入非介面類型、聯集和底層類型的集合。
當作為類型約束使用時,介面定義的類型集合確切地指定了允許作為類型參數的特定類型參數類型引數。在通用函數主體中,如果操作項的類型是具有約束 C 的類型參數 P,則如果操作項在 C 的類型集合中的所有類型中都被允許,則允許操作(目前某些實現限制,但一般代碼不太可能遇到它們)。
用作約束的介面可以給出名稱(例如 Ordered),或者它們可以是內嵌在類型參數清單中的文字介面。例如
[S interface{~[]E}, E interface{}]
在這裡 S 必須是切片類型,其中元素類型可以是任何類型。
由於這是一個常見的情況,對於約束位置的介面可能會省略封閉的 interface{},我們可以簡單地寫成
[S ~[]E, E interface{}]
由於空介面在類型參數清單中很常見,而且在普通的 Go 程式碼中也是如此,因此 Go 1.18 引入了新的預宣告識別碼 any 作為空介面類型的別名。有了它,我們就有了這個慣用語法代碼
[S ~[]E, E any]
作為類型集合的介面是一種強大的新機制,是讓 Go 中的類型約束起作用的關鍵。現在,使用新語法形式的介面只能用作約束。但是,不難想像明確地類型約束的介面如何普遍有用。
類型推論
最後一個重大新語言功能是類型推論。在某些方面,這是對語言最複雜的更改,但這很重要,因為它允許人們在撰寫呼叫通用函數的代碼時使用自然樣式。
函數參數類型推論
有了類型參數,就有必要傳遞類型引數,這會使代碼冗長。回到我們的通用 GMin 函數
func GMin[T constraints.Ordered](x, y T) T { ... }
類型的參數 T 必須用來規定一般型別引數 x 以及 y。如我們先前所見,這可以用明確的類型引數呼叫
var a, b, m float64
m = GMin[float64](a, b) // explicit type argument
在很多情況下,編譯器可以由一般的引數推斷出 T 的類型引數。這在保留明確的同時縮短程式碼。
var a, b, m float64
m = GMin(a, b) // no type argument
這種運作會將引數 a 和 b 的類型與參數 x 以及 y 的類型配對。
這種從函式引數類型推断類型引數的推斷稱為函數引數類型推斷。
函數引數類型推斷只對函式參數中使用的類型參數有效,對只在函式結果或只在函式主體中使用的類型參數無效。例如,它不適用於 MakeT[T any]() T 等函式,因為只在結果中使用 T。
約束類型推斷
此語言支援另一種類型推斷,約束類型推斷。為了闡述,讓我們從調整一組整數的範例開始
// Scale returns a copy of s with each element multiplied by c.
// This implementation has a problem, as we will see.
func Scale[E constraints.Integer](s []E, c E) []E {
r := make([]E, len(s))
for i, v := range s {
r[i] = v * c
}
return r
}
這是一個通用函式,可以使用於任何整數類型的陣列。
現在假設我們有維度超過 1 的 Point 類型,其中每個 Point 只是給定點的座標清單。這種類型當然會有方法。
type Point []int32
func (p Point) String() string {
// Details not important.
}
有時我們會想調整 Point。因為 Point 只是一組整數,所以我們可以使用我們先前編寫的 Scale 函式。
// ScaleAndPrint doubles a Point and prints it.
func ScaleAndPrint(p Point) {
r := Scale(p, 2)
fmt.Println(r.String()) // DOES NOT COMPILE
}
不幸的是,這無法編譯,而且會失敗並產生像「r.String 未定義(類型 []int32 沒有 String 欄位或方法)」的錯誤訊息。
問題是 Scale 函式傳回 []E 類型的值,其中 E 是引數陣列的元素類型。在我們使用 Scale 呼叫 Point 類型時(它底層類型是 []int32),會傳回 []int32 類型的值,而不是 Point 類型。這是因為通用程式碼的寫作方式,但並非我們想要的。
為了修正這個問題,我們必須變更 Scale 函式,對陣列類型使用類型參數。
// Scale returns a copy of s with each element multiplied by c.
func Scale[S ~[]E, E constraints.Integer](s S, c E) S {
r := make(S, len(s))
for i, v := range s {
r[i] = v * c
}
return r
}
我們引進新的類型參數 S,其為切片參數的類型。我們約束它使底層類型為 S,而非 []E,而且結果類型現在是 S。由於 E 約束為整數,因此效應與先前相同:第一個參數必須為某種整數類型的切片。函數主體唯一的變更在於現在我們呼叫 make 時傳遞 S,而非 []E。
如果我們以一般切片呼叫新函數,它會像以前一樣動作,但是如果我們使用 Point 類型呼叫它,我們現在會收到 Point 類型的值。這就是我們想要的。有了此版本的 Scale,較早的 ScaleAndPrint 函數會如我們預期編譯並執行。
但是,合理的疑問是:為什麼可以在不傳遞明確類型參數的情況下寫入對 Scale 的呼叫?也就是說,為什麼我們可以寫入 Scale(p, 2),而不傳遞類型參數,而不是寫入 Scale[Point, int32](p, 2)?我們的新 Scale 函數具有兩個類型參數,S 和 E。在不傳遞任何類型參數的情況下呼叫 Scale 時,上文說明的函數參數類型推論會讓編譯器推論 S 的類型參數為 Point。但是函數還有一個類型參數 E,這是乘法因素 c 的類型。對應的函數參數為 2,而且因為 2 是無類型常數,所以函數參數類型推論無法推論 E 的正確類型(充其量只能推論 2 的預設類型,即 int,這是錯誤的)。相反,編譯器藉由推論 E 的類型參數為切片的元素類型這個處理程序稱為約束類型推論。
約束類型推論會從類型參數約束中推論類型參數。當一個類型參數有約束時,則會使用約束類型推論,而約束是以另一個類型參數來定義的。當其中一個類型參數的類型參數已知時,會使用約束來推論另一個類型參數。
此狀況通常會應用在一個約束使用 ~類別 表單對某些類別時,而類別是用其他類別參數編寫的。我們可以在 Scale 範例中看到。S 是 ~[]E,也就是 ~ 後面接著使用另一類別參數編寫的類別 []E。如果我們知道 S 的類別引數,我們就可以推論 E 的類別引數。S 是切片類別,而且 E 是該切片的元素類別。
這只是約束類別推論的介紹。如需完整詳細資料,請參閱 提案文件 或 語言規格。
實際上的類別推論
類別推論如何運作的詳細資料很複雜,但實際上並不困難:類別推論只能成功或失敗。如果成功,就可以省略類別引數,而呼叫通用函數看起來跟呼叫一般函數沒有什麼不同。如果類別推論失敗,編譯器會傳送錯誤訊息,在這種情況下,我們只需要提供必要的類別引數即可。
我們在語言中加入類別推論時,試著在推論能力與複雜度之間取得平衡。我們想要確保當編譯器推論類型時,這些類型永遠不會令人驚訝。我們已努力小心地選擇站在推論失敗的那一方,而不是站在推論錯誤類別的那一方。我們可能沒有完全做對,而且我們可能會在未來的版本中持續改良它。最終結果是可以在不用明確提供類別引數的情況下撰寫更多程式。目前不需要類別引數的程式在之後也不需要。
結論
泛型是 1.18 版本中一個重大的新語言功能。這些新的語言變更需要大量新的程式碼,而這些程式碼並未在生產環境中進行大量測試。這只有在更多人撰寫並使用泛型程式碼後才會發生。我們相信此功能已獲得良好的實作而且品質很高。不過,與 Go 的大多數面向不同,我們無法透過實際的經驗來支持這個信念。因此,儘管我們鼓勵在有意義的情況下使用泛型,但在生產環境中部署泛型程式碼時,請採取適當的預防措施。
撇開這些警告,我們很高興泛型已推出,並且我們希望它們能讓 Go 程式設計師的生產力更高。
下一篇:Go 如何減輕供應鏈攻擊
上一篇:Go 1.18 發布!
部落格索引