Go 部落格
在 Go 中建立 LLM 驅動的應用程式
由於 LLM (大型語言模型)及其周邊工具(如內嵌模型)在過去一年的功能大幅提升,越來越多的開發人員考慮在其應用程式中整合 LLM。
由於 LLM 通常需要專用硬體和大量的運算資源,因此它們最常打包為提供 API 以存取的網路服務。 OpenAI 或 Google Gemini 等領先 LLM 的 API 就是這樣運作的;甚至像 Ollama 這樣的自訂 LLM 工具也會將 LLM 包裝成一個 REST API 以供本地使用。此外,在應用程式中利用 LLM 的開發人員通常需要向量資料庫等補充工具,而這種工具最常也部署為網路服務。
換句話說, LLM 驅動的應用程式與其他現代雲端原生應用程式非常相似:它們需要出色的 REST 與 RPC 協定、並行性和效能支援。這些恰好是 Go 最擅長的領域,使其成為撰寫 LLM 驅動的應用程式的一種絕佳程式語言。
這篇文章將透過一個使用 Go 編寫的簡單 LLM 應用範例進行說明。它首先描述此示範應用程式解決的問題,並繼續展示幾個應用程式變體,這些變體都執行相同的任務,但使用不同的套件來執行。這篇文章中所有示範的程式碼皆 已在線上公開。
用於問答的 RAG 伺服器
一種常見的 LLM 應用程式技術是 RAG - 檢索強化產生。RAG 是為特定網域互動客製化 LLM 知識庫最具擴充性的方式之一。
我們將使用 Go 建立一個RAG 伺服器。這是一個會提供兩個操作給使用者的 HTTP 伺服器
- 將文件新增至知識庫
- 詢問 LLM 關於此知識庫的問題
在典型的實際情況中,使用者會將文件語料庫新增至伺服器,並繼續詢問問題。例如,一家公司可以利用內部文件填滿 RAG 伺服器的知識庫,並使用它來提供由 LLM 驅動的問答功能給內部使用者。
以下是顯示我們的伺服器與外部世界互動的圖表
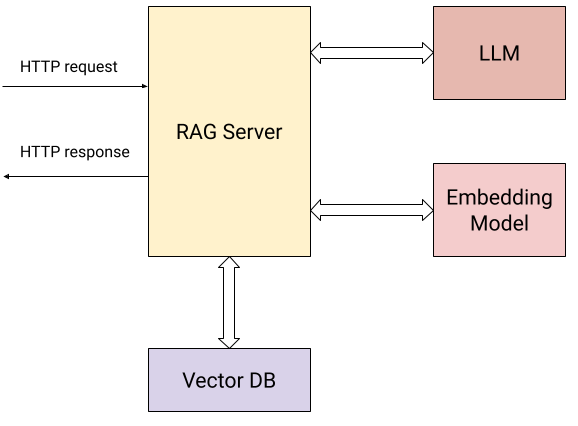
除了使用者傳送 HTTP 要求(上面描述的兩個操作)之外,伺服器會與下列項目進行互動
- 一個嵌入式模型,計算已提交文件的 向量嵌入 和使用者的問題。
- 一個向量資料庫,用來有效率地儲存及擷取嵌入式。
- 一個 LLM,用來根據從知識庫收集的內容詢問問題。
具體來說,伺服器會對使用者公開兩個 HTTP 端點
/add/: POST {"documents": [{"text": "..."}, {"text": "..."}, ...]}:將一系列文字文件提交至伺服器,以新增至其知識庫。對於這個要求,伺服器將
- 使用嵌入式模型為每個文件計算向量嵌入。
- 將文件連同其向量嵌入儲存在向量資料庫中。
/query/: POST {"content": "..."}:提交一個問題至伺服器。對於這個要求,伺服器將
- 使用嵌入式模型計算問題的向量嵌入。
- 使用向量資料庫的相似性搜尋,在知識資料庫中找出與問題最相關的文件。
- 使用簡單的提示工程,使用步驟 (2) 中找到的最相關的文件作為背景,重新表述問題,並將其傳送至 LLM,將其答案傳回給使用者。
我們的示範所使用的服務為
- Google Gemini API,用於 LLM 和嵌入模型。
- Weaviate,用於本機託管的向量資料庫;Weaviate 是一款使用 Go 實作 的開源向量資料庫。
使用其他等效服務取代這些服務應該很容易。事實上,伺服器的第二個和第三個變體都是關於這一點的!我們將從直接使用這些工具的第一個變體開始。
直接使用 Gemini API 和 Weaviate
Gemini API 和 Weaviate 都有便利的 Go SDK(用戶端程式庫),而我們的第一個伺服器變體直接使用這些 API 和 SDK。這個變體的完整程式碼 在此目錄。
我們不會在此網誌文章中重現所有程式碼,但以下是閱讀時應記住的一些注意事項
結構:任何在 Go 中撰寫過 HTTP 伺服器的人都會對程式碼結構感到熟悉。為 Gemini 和 Weaviate 初始化用戶端程式庫,並將用戶端儲存在傳遞至 HTTP 處理常式的狀態值中。
路由註冊:我們伺服器的 HTTP 路由使用 Go 1.22 中引入的 路由強化功能 設定,十分容易。
mux := http.NewServeMux()
mux.HandleFunc("POST /add/", server.addDocumentsHandler)
mux.HandleFunc("POST /query/", server.queryHandler)
並行性:我們伺服器的 HTTP 處理常式透過網路聯繫其他服務並等待回應。這對 Go 來說不是問題,因為每個 HTTP 處理常式在它自己的 goroutine 中並行執行。這個 RAG 伺服器可以處理大量並行的要求,而每個處理常式的程式碼都是線性的和同步的。
批次 API:由於 /add/ 要求可能會提供大量的文件加入知識庫,因此伺服器使用批次 API,同時對嵌入 (embModel.BatchEmbedContents) 和 Weaviate DB (rs.wvClient.Batch) 處理,以提升效率。
使用 LangChain for Go
我們的第二個 RAG 伺服器變體使用 LangChainGo 執行相同的任務。
LangChain 是一個廣泛使用的 Python 框架,用於建構 LLM 驅動的應用程式。 LangChainGo 是它的 Go 等效項。此框架有一些工具,可以用於從模組組成架構建應用程式,並在共用 API 中支援多個 LLM 提供者和向量資料庫。這讓開發人員可以撰寫可能會與任何提供者合作並輕易變更提供者的程式碼。
這個變體的完整程式碼 在此目錄。閱讀程式碼時,你將會注意到兩件事
首先,它比之前的變體稍微短一些。LangChainGo 負責將向量資料庫的完整 API 包裝成常見介面,初始化與處理 Weaviate 所需的程式碼更少。
第二,LangChainGo API 讓人很容易更換供應商。假設我們想要用另一個向量資料庫取代 Weaviate;在我們之前的變體中,我們必須將介接向量資料庫的所有程式碼重寫為使用新的 API。有了像 LangChainGo 一樣的框架,我們不再需要這麼做。只要 LangChainGo 支援我們有興趣的新向量資料庫,我們就能在伺服器中取代極少數的程式碼行,因為所有資料庫都實作常見介面
type VectorStore interface {
AddDocuments(ctx context.Context, docs []schema.Document, options ...Option) ([]string, error)
SimilaritySearch(ctx context.Context, query string, numDocuments int, options ...Option) ([]schema.Document, error)
}
使用 Go 的 Genkit
今年初,Google 發布了Go 的 Genkit—一個用來建置由 LLM 驅動的應用程式的全新開源架構。Genkit 與 LangChain 有些特徵相同,但在其他方面有所不同。
和 LangChain 一樣,它提供不同供應商(以插件形式)可以實作的常見介面,因此從一個供應商換成另一個供應商更為容易。然而,它不會試著規範不同的 LLM 元件如何互動;相反地,它專注於生產功能,例如提示管理與工程,並與整合的開發人員工具進行部署。
我們的第三個 RAG 伺服器變體使用 Go 的 Genkit 來完成相同任務。其完整程式碼在此目錄中。
此變體和 LangChainGo 的變體相當類似——LLM、嵌入器與向量資料庫的常見介面用來取代直接的供應商 API,這使得從一個變體切換到另一個變體更容易。此外,使用 Genkit 將由 LLM 驅動的應用程式部署到生產環境會容易得多;我們沒有在我們的變體中實作這個功能,但如果你有興趣,可以閱讀文件。
摘要——Go for 由 LLM 驅動的應用程式
本篇文章中的範例僅提供在 Go 中建置由 LLM 驅動的應用程式時,可以做到的一些事項。它說明了用相對少的程式碼建置強大的 RAG 伺服器有多麼容易;最重要的是,這些範例因為 Go 的一些基本功能,而具備相當程度的生產準備狀態。
使用 LLM 服務通常意味著將 REST 或 RPC 要求傳送給網路服務,等待回應,再根據該回應向其他服務傳送新的要求,以此類推。Go 非常擅長所有這些,提供強大的工具來管理並行作業與協調網路服務的複雜性。
此外,Go 身為原生雲端語言擁有出色的效能與可靠性,使其成為實作 LLM 生態系中基礎建構模組的自然選擇。若要取得一些範例,請參閱下列專案:Ollama、LocalAI、Weaviate 或 Milvus。
下一篇文章:(別名)名字有什麼含意?
上一篇文章:分享您使用 Go 進行開發的意見回饋
部落格索引